How can voice-based conversational AI increase the accessibility of tax declaration forms? This project explored new ways to make government forms more accessible, especially for those who struggle with traditional text interfaces.
Background & Challenge
Many people find tax forms confusing and inaccessible. We set out to design a system that could guide users through the process using natural language, reducing barriers and increasing confidence.
Research & Design
First we developed a system which would use a conversational agent on the phone to guide a user through the process of filling in a form. We wanted to simulate a call to customer service, and used zero-shot prompting along with a knowledgebase in order to give the agent all the information that a user might ask for in a form-filling context.

We tested this system with users, and found that they could navigate the complex form better with the help of the voice agent. However, following the model of a customer service helpline had some downsides - the agent and user had different contexts, and communication broke down when the user asked about "the next question" or "the bottom of the page".
A multimodal conversational interface
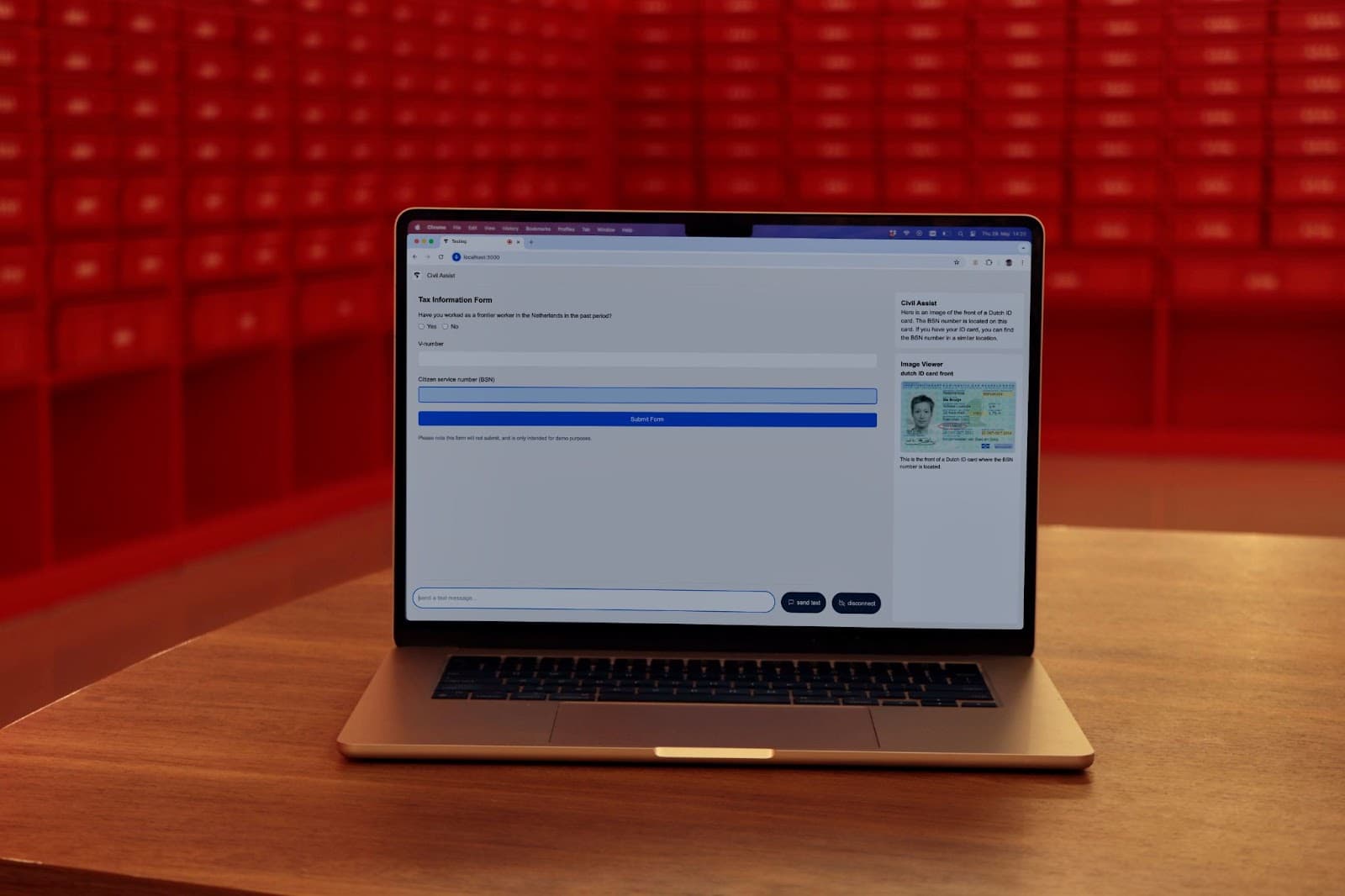
We devised a new prototype that would take advantage of multi-modal conversational AI. This design integrated voice interaction with support onscreen - it could be integrated in an online form and supported features such as highlighting form fields and displaying images. This prototype still spoke to users with a voice, but also provides a transcription of the spoken words.
Results & Reflection
The prototypes showed promise in making tax forms more accessible and less intimidating. We also got some interesting feedback from the users. Although it was helpful and clear, the voice we used in the prototype surprised some users. One participant remarked "Is this the voice that will tell me I'm in debt to the Belastingdeinst? It sounds like it's about to make a joke!" This led to another interesting piece of research Calling all Citizens, in which I explore more the appropriate and most trustworthy synthetic voice in a given public context.